Memo_玄学统计:反思实证研究的可复制性
去年在《美国国家科学院院刊·社会科学版》(Proceedings of the National Academy of Sciences, PNAS)上刊登了一篇文章很有意思,这篇文章题为《Observing Many Researchers Using the Same Data and Hypothesis Reveals a Hidden Universe of Uncertainty》,和前段时间拿了奥斯卡的《瞬息全宇宙》一样(但我更喜欢台湾译法《妈的多重宇宙》),如果俏皮些翻译,或许可以把这篇文章译成《(妈的)玄学统计宇宙》。邻近毕业季,正在凑玄学显著的同学们想必很有同感。
这篇论文由160余位、来自73个研究团队的社会科学家共同合写,主要是德国、英国及奥地利等欧洲国家的学者,他们的核心发现是:第一,尽管召集了学界同仁一起用同一份数据,检验同一个假设,但最终学者们报告的统计结果与主观结论相差极大,这个结论并不新鲜,早在2009年如Young就在ASR上批评过Barro和McCleary就宗教与经济增长关系的模型很不稳定;第二,就上述差异而言,召集者进一步调查了学者背景以控制潜在的学术偏见、编码了学者们数据分析的具体过程以控制潜在的操作化差异,统计结果的变异(Variance)仍然有95.2%是无法被解释的,且就文字性的主观结论而言,变异仍有80.1%无法被解释,这点是这篇论文的核心。
换言之,这项研究拒绝了已往学界偶尔会诟病的实证研究难被复制或结论不一的原因,即可能是因为学者事前有偏见、或者操作化过程中有主观处理的差异,但这项研究提出了一个比以往质疑更具挑战性的问题,即上述的猜测如果仅能解释很小一部分实证结果的差异(大约5%),那么剩下95%的统计变异应该如何解释?或者说,我们仍然不清楚为什么社会科学家们会拿着同一份数据,但跑出来不同结果,最后大家把这个玄学问题发到PNAS或许是最好的结果了。
一、《(妈的)玄学统计宇宙》的方法与结论
尽管这篇论文的正文只有8页,但附录了190页更详细的处理过程,且相关的处理代码可以在Github上找到。就正文内容,我们可以扼要如下三个部分,为啥要做这个研究、怎么做的、得到了什么结论?
(一)论文背景
就实证研究而言,在西方学界,尤其是心理学界,近些年持续推动着元科学(Metascience Research)的复制性研究,但很多复制性的工作都失败了,
比较主流的回应是Gelman和Loken在《美国科学家》杂志上写的一篇短文《科学中的统计危机》,讲数据处理的决策过程有“岔路花园”(Garden of Forking Paths),其一是学者们本身存在能力差异,不同专业水平可能会有不同的数据处理策略,其二是科学生产中有主观的偏见,使研究过程存在系统性扭曲,进而降低了可复制性。这篇则进一步补充谈到,科学分析过程事实上非常复杂且模糊,尽管每一个数据处理的决策非常微小,但累积起来可能会根本性地改变结论。
尽管最近二十年,越来越多的期刊要求提供稳健性检验,但研究人员的变异性评估大致上是最近五年才开始的,事实上,大多数团队的结果就是不一致的。这方面比较典范的工作是Botvinik-Nezer等(2020)、Menkveld等(2022)分别让65、164个团队做实证研究的可复制性测试,但这些工作仍然没有解释为什么社会科学家们就同一份数据得出结论不一致,这篇文章的主要推进就是,如果把所有团队数据处理流程的每一步都进行编码,可能会解释团队间得出结论的差异么,有没有什么关键的决策步骤影响了这个差异?(但就像我们开头已经剧透的,尽管编码非常细致,这篇论文仍然失败了。)
(二)论文方法
就具体的讨论而言。首先是筹备方面。其一,参与人有多少、有哪些?召集人团结了73个团队、161个学者,实际参与的学者中有46%是社会学的、25%是政治学的,其余是经济学等学科,83%的学者有统计学教学经验、70%的学者至少发表过一篇移民相关论文。其二,检验什么问题?检验一个经典的移民研究假设:“移民数量会减少公众对社会政策的支持。”这个问题对来自政治学、社会学、经济学、地理学等诸学科的社会科学家们都很有吸引力,是一个已经被广为讨论的议题。其三,检验用什么数据?大家共同使用的数据是国际社会调查(International Social Survey Pro- gram, ISSP)五期数据(1985、1990、1996、2006、2016),同时召集人提供了世界银行、联合国和经合组织整理的移民存量(Stock,即移民占总人口百分比)与移民流量(Flow,即年流量净变化)数据。其四,检验以后怎么进行后续分析?这需要提前让大家提供相对规范的模型结果。一方面,为了控制潜在偏见,召集人提前测量了参与者的专业知识、研究信念及态度等,同时,所有参与者也都在结束后,对随机的五、六个其他团队的模型质量打分,构建一个模型排名变量,另一方面,各团队开始分析前,需要先提交研究计划,且最终提交报告包含的统计结果是标准化效应,并提供三分类的主观结论(支持原假设、拒绝原假设、或不认为该数据可检验假设)。
其次是具体分析方面。其一,有哪些可分析数据?经召集人整理,各团队提交了有效模型1261个、有效团队结论89个。其二,变量怎么处理?各团队使用的方法当然有很多,有的用多层次模型去调整国家、年份差异,有的则是使用固定效应模型去控制,有的则是用虚拟变量去控制,还有使用最大似然或贝叶斯估计,而不是最小二乘的,这些都会被召集人编码。召集人进一步对获得的模型/报告进行人工识别,确定了166个研究设计决策,如变量测量(Measurement Strategy)、估计方法(Estimator)、层次结构(Hierarchical Structure)、自变量的选择、数据集、使用软件、参与者对主题或方法的熟悉程度、以及前文已调查的潜在信念。为了防止估计偏差,召集人最后使用了这166个研究设计决策中有107个同时被三家及以上团队选择使用的研究设计决策。其三,模型怎么设计?由于移民变量有两种,一个是存量、一个是流量,为了使二者可比,召集人们又将上述模型转化为平均边际效应(AME)。同时,在统计结果模型中,为了解释总体、团队间、团队内变异,使用了多层次回归,在主观结果模型中,为了解释三分类差异,使用了多项Logistics回归。且为了防止过拟合,变量是按分组/分阶段输入并只保留使可解释变异增加的变量,如先输入“设计”决策时因变量怎么测量的(有六个问题可以作为因变量),随后输入“测量”决策时自变量怎么测量的(二分、有序、多项还是连续)、随后如“数据样本”决策、“模型设计”决策、“研究人员特征”。为了检验分阶段稳健性,召集人还使用了一种算法以组合所有变量,但这个模型存在过拟合风险,乃及对所有变量交互项(5565个)进行检查,这部分由于较为复杂,读者如对上述具体操作感兴趣,可以参见这篇论文更具体的附录,总之,论文通过更复杂模型的讨论,论证了其分组/分阶段进行讨论的合理性。
(三)论文结论
最后,是这篇论文的结论部分(当然,由于开头的剧透,这里其实只是更具体的数据吐槽)。我们可以直接看论文提供的两张图。
图1显示了73家团队的AME统计结果差异,最下面的圈意思是有25.4%的团队做出来负向影响、57.7%的团队做出了包含0的区间结果、16.9%的团队做出了正向影响。主观结果差异事实上呈现了类似结果,13.5%认为无法检验、28.5%认为支持假设(即负向影响)、60.7%认为拒绝假设。
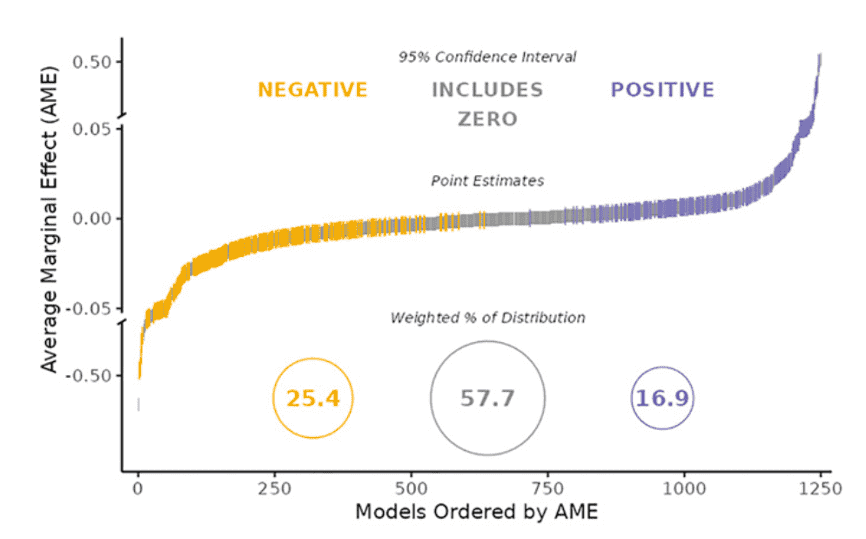
图2显示了107个决策点几乎不能解释统计结果的变异。从第一行的总体变异看,研究设计(绿色)只能解释2.6%的差异、学者特征(紫色)也仅能解释1.2%,而95.2%的结果变异是无法被解释的,也就是说,一些数据分析过程中的特殊决策,论文并未捕捉到。从第四行的、主观结论的团队间变异看,无法被解释的差异仍然有80.1%,但这包括了每个团队所得出模型在统计上支持其结论的测试结果(粉色部分)。也就是说,即便仔细观察学者们的处理数据的决策过程、考虑学者们的特征,仍然几乎无法解释为什么大家的结论会相差这么大。
同时,召集人对所有潜在的可能进一步多元宇宙模拟(Multiverse Analysis),得到了2304个模型,与实际的4.8%的可解释性相比,模拟的模型解释度提高到16%,但是这仍然对理解变异有很大差距。至此,这篇论文认为,他们挖掘到了一个潜在的(妈的)研究者可变性宇宙(A Hidden Universe of Idiosyncratic Researcher Variability),且对这一宇宙暂时还不能理解(摊手)。

二、迈向开源的实证社会科学
最后,虽然学者们仍然不清楚到底这个不确定性宇宙到底是什么样的,这篇论文提出了几条建议:第一,复制是有价值的,但是还不够,还需要评估不同学者是否能够得到相似结论,这会增强或削弱我们对特定知识的信心,学界就某一问题经年争论所形成的共识仍然具有意义,与之相对,单一学者得出的结论,哪怕是非常客观、实证,我们仍然需要谨慎对待。第二,定量实证研究者要谨慎地、尽可能记录一切操作过程,因为微小细节的累积很可能导致完全不同的结论。第三,科学家是否有偏见可能没有我们想象的那么重要,只要他们提供模型的细节,就可以帮助我们理解真实世界。
事实上,国际社会科学界就可复制性的争论,在国内并不是一件新鲜事。《社会学研究》杂志社在19年就曾刊发过吴开泽老师与读者布文的讨论,来回交流有多篇文章。这篇文章则为我们理解这些年国内外定量实证研究的持续的可复制性争论,提供了一个进一步解释,即大量的实证研究不仅在数据处理细节方面存在很大的主观性乃及不可见性,更重要的是,我们目前仍然不能确定定量实证研究的不确定性来自哪里,这一不确定性因人、因时而异,这使学者们在因果推断方面仍然要保持极大的谨慎。
当然,诚如这篇论文讨论的,尽管我们目前对个体分析所得到的结论要保持谨慎,但在最近几年,出现了一个新的方法,即前文已提及的多元宇宙分析(Multiverse Analysis),如Steegen等(2016)提出的,对一组合理的情景进行分析、对整个数据集采用多个不同的分析方法,可以在一定程度提高稳健性。同时,社会科学界可以持续地推进开源的、可复制的、协作性的社会科学研究,搭建定量实证论文的开源代码平台,通过不断的迭代,得到更扎实的学术共识。
参考文献
[1] Breznau N., Rinke E.M., Wuttke A., et al., 2022, “Observing Many Researchers Using The Same Data and Hypothesis Reveals A Hidden Universe of Uncertainty”, Proceedings of The National Academy of Sciences, 119(44), e2203150119.
[2] Steegen S., Tuerlinckx F., Gelman A., et al., 2016, “Increasing Transparency Through a Multiverse Analysis”, Perspectives on Psychological Science, 11(5), 702-712.
[3] Young C., 2009, “Model Uncertainty in Sociological Research: An Application to Religion and Economic Growth”, American Sociological Review, 74(3), 380-397.
注:本文为“严肃的人口学八卦”微信号供稿。